Fine Tune DistilBERT
Transformers האיצו את עולם עיבוד השפה למרחקים חדשים במגוון היבטים. במאמר הזה נלמד מה זה אומר בכלל Transformers? מה זה אומר BERT? מה הקשר שלהם למודלי LLMs? לאחר מכן, באמצעות Synthetic Dataset אותו יצרנו במאמר הקודם נאמן מחדש מודל DistilBERT
Transformers #
איך הם עובדים? למה הם מנצחים ב-Sequence Problems מודלים מסוג Recurrent Neural Networks (ידועים כ-RNN), Gated Recurrent Units (ידועים כ-GRU) ו-Long Short-Term Memory (ידועים כ-LSTM)? מה בכלל אמרתי?
Attention is All You Need #
המאמר ״Attention is All You Need״ מ-2017 הביא לחידוש בתחום, הציג רשת נוירונים חדשה בשם “Transformers”. המבנה של ה-Transformers מתבסס על ארכיטקטורת קידוד (encode) ופענוח (decode) בעזרת Attention.

כדי להבין את העקרונות הבסיסיים של מנגנון ה-Attention, בואו נבחן דוגמה של Generation Model שכותב סיפור דרמה. בהתחלה, המודל מקבל קלט, מעבד אותו, ומפיק פלט. לאחר מכן, אנו מזינים שוב את הקלט המקורי יחד עם הפלט הקודם, וכך מאפשרים למודל לייצר פלט נוסף. תהליך זה מאפשר למודל לבנות סיפור דרמה, המבוסס על הקלט ההתחלתי, תוך שהוא מתחשב בהתפתחות העלילה.
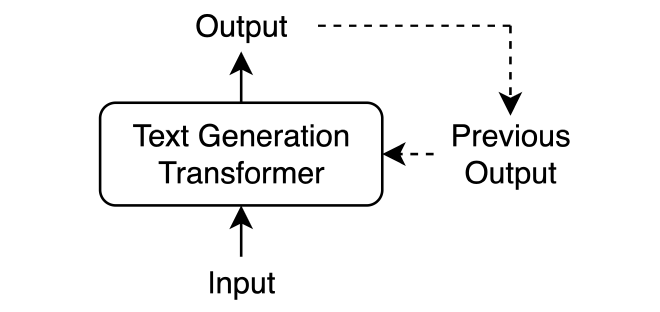
כשהמודל יוצר טקסט, הוא עושה זאת מילה אחרי מילה, כשבכל מילה שהוא מייצר, הוא יכול להסתמך (Reference) על מילים קודמות שקשורות לה. במהלך האימון, ובפרט בשלב ה-’Backpropagation’, המודל לומד להבין את הקשרים שבין המילים, מה שמאפשר לו לייצר טקסט בהקשר (Context) הנכון.
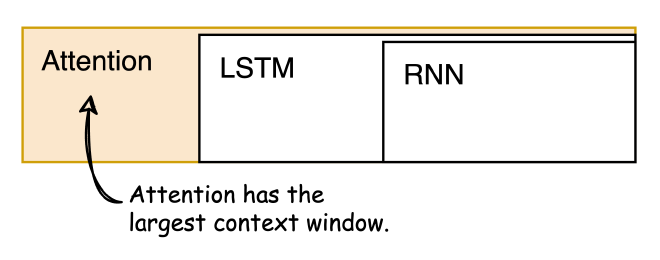
בניגוד למודלי Sequence Problems אחרים, המנגנון המבוסס על Attention לא נתקל בבעיית זיכרון לטווח קצר. הוא מסוגל ליצור טקסט תוך שמירה על הקשרים ארוכי טווח, וזאת על ידי התחשבות בזרימה השוטפת של הטקסט.
מה זה אומר בפועל? הטקסט נכנס למודל כ"רצף קלט" - נתונים המוזנים בסדר מסוים, שבו הסדר הזה חשוב לעיבוד. המקודד (encoder) של המודל מתרגם את הרצף הזה לייצוג אבסטרקטי, שבו מאוחסן כל המידע שהמודל צבר מהקלט. לאחר מכן, המפענח (decoder), לוקח את הייצוג האבסטרקטי הזה ופועל ליצירת הפלט שלב אחר שלב. במהלך התהליך הזה, המפענח מתייחס בנוסף לקלט גם לפלטים שנוצרו בעבר. בדרך זו המודל מסוגל להגיב בצורה מדויקת לקלט המקורי.
נפרק ונרכיב.
Input Embedding #
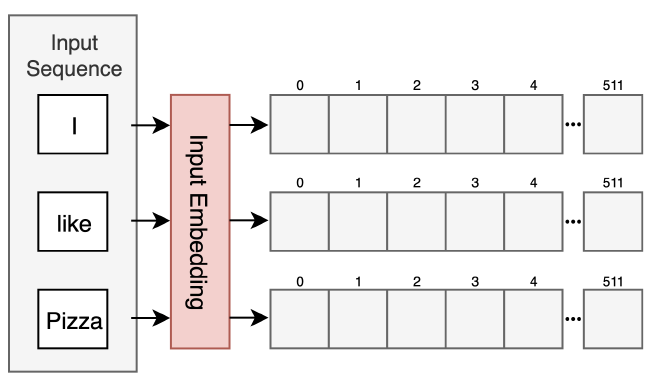
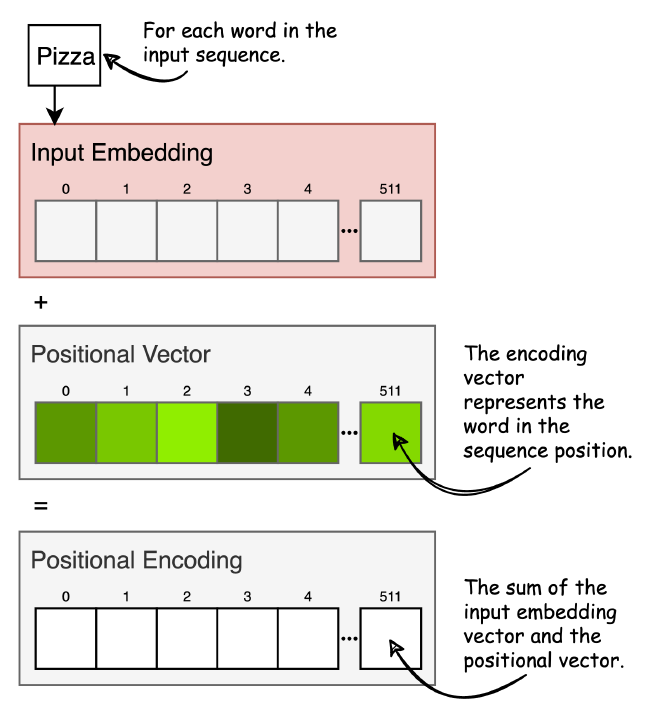
כל מילה במשפט (input sequence) מתורגמת לוקטור עם ערכים רציפים (word embedded) שמייצגים את המילה במרחב. הוקטורים הללו הוגדרו מראש ב-Dictionary, וגודלם הוא 512 מימדים. הרעיון המרכזי מאחורי כל וקטור, הוא שלמילים עם משמעות סמנטית דומה יש ייצוג במרחב דומה. להרחבה בנושא, ראו מאמר Word2Vec שכתבתי. אחרי ששכבת Input Embedding מייצרת וקטור עבור כל מילה במשפט, נעבור לשכבה הבאה, Positional Encoding.
Positional Encoding #
יש לנו עכשיו אוסף של וקטורים, כאשר כל וקטור מייצג מילה. הבעיה היא שאנחנו לא מביאים לידי ביטוי איזו מילה באה לפני אחרת. לשם כך, לפני שנכניס את הוקטורים ל-Encoder, עבור כל וקטור נוסיף מידע על המיקום היחסי שלו במשפט. לפני שנמשיך, למה זה משנה?

אפשר לראות בצורה ברורה, למיקום של המילים יש השפעה ישירה על משמעות המשפט.
על מנת שנוכל להוסיף קידוד למיקום של כל מילה ומילה, נצטרך למצוא דרך שתענה על הקטגוריות הבאות:
- Unique encoding for each time-step - חשוב שלכל מיקום ברצף יהיה ייצוג מיקומי שונה, וכך נוכל לאפשר למודל להבחין בין מיקומים שונים במשפט.
- Consistent distance between any two time-steps - המודל צריך להיות מסוגל לזהות באופן עקבי את המרחק בין שני מיקומים ברצף. בדרך כלל, זה אומר שקידוד המיקום צריך להשתנות באופן הדרגתי ככל שמתקדמים ממיקום אחד לאחר.
- Should generalize to longer sentences - מערכת הקידוד צריכה להתאפשר לעבודה עם משפטים באורכים שונים. לא להגביל לעבודה עם משפטים באורך קבוע, ובאופן אידיאלי לתמוך במשפטים ארוכים יותר מאלה שנראו במהלך האימון.
- Deterministic - התהליך של יצירת קידודים מיקומיים צריך להיות דטרמיניסטי, כלומר, מיקום מסוים צריך תמיד להניב את אותו הקידוד. עקביות זו חיונית כדי שהמודל ילמד באופן אמין תלות מיקומית.
החוקרים גילו שאפשר להשתמש בפונקציות סינוס וקוסינוס כדי ליצור קידוד ייחודי לכל מילה במשפט, ושהתנאים עליהם דיברנו מעלה ילקחו בחשבון. הפונקציות הללו מיצרות וקטורים של באורך זהה ל-input embedding. באיור מטה תוכלו לראות ששורה היא הוקטור שנוסיף לוקטור המייצג מילה, וכל עמודה מייצגת מימד שונה (לשם ההמחשה הורדתי ל-100 מימדים). הדפוס שנוצר נראה כפסי זברה, כאשר מיקומים זוגיים משתמשים בסינוס ואי-זוגיים בקוסינוס. זו שיטה יעילה שעוזרת למודל לזהות את מיקום כל מילה.
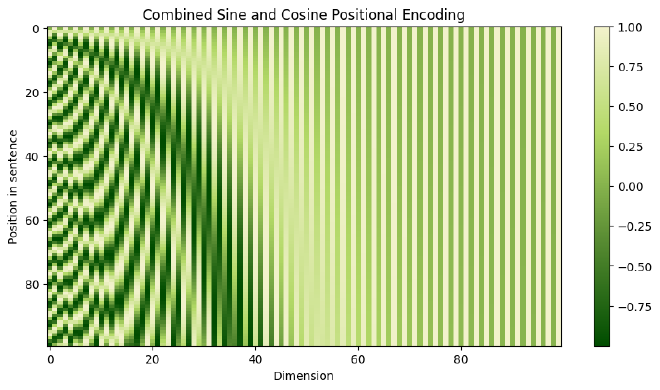
נוסיף את הווקטורים ל-Input Embedding המתאים. כך נוכל לאפשר למודל לדעת את המיקום היחסי של הוקטורים ולהבין משמעויות מכך. פונקציות הסינוס והקוסינוס נבחרו יחד מכיוון שיש להן תכונות לינאריות - בדומה לסדר של כל מילה ומילה. להרחבה בנושא. לאחר שכבה זו, הקלט נקרא ״Input Sequence״.
Encoder Layer #
שכבת ה-Encoder מעבדת את Input Sequence לחילוץ מידע חשוב, כך שהמודל יוכל בסופו של דבר להבין את משמעות הקלט ולייצר פלט מתאים. לשכבה זו מספר מרכיבים, ולכל אחד מטרה ייעודית.
Self-Attention #
מנגנון Self-Attention מאפשר ל-Inputs לראות אחד את השני (“self”), ולמצוא למי הם צריכים לתת יותר תשומת לב (“attention”). הפלט הוא ההשוואה הזו, עם ציונים של כל מילה יחסית למילה אחרת במשפט.
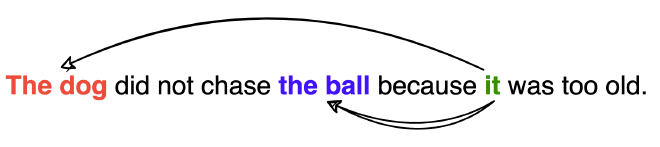
במשפט מטה, המילה “it” מתייחסת לרחוב או לחיה? לנו זה ברור, שרחוב לא יכול להיות עייף, אבל למודל זה יותר קשה. Self-Attention זהו מנגנון שמאפשר למילה להגיד כמה רלוונטית מילה יחסית לכל מילה אחרת במשפט, כדי להגיע להבנה של יחסי המילים במשפט, ומשמעות המשפט באופן כללי.
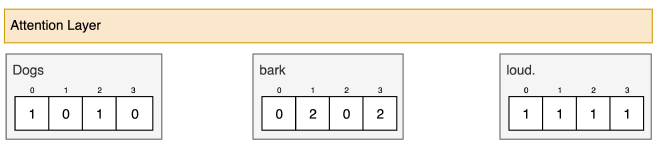
צעד 1: הכנת Inputs #
נתחיל ביצירת וקטור לכל מילה במשפט. לשם ההדגמה, כל הוקטורים הם 4 מימדים. מזכיר שאנחנו אחרי ביצוע תהליך Position Encoding, ובכל וקטור מוטמע גם המיקום שלו במשפט.
צעד 2: יצירת מטריצות משקלים #
מטריצות הטלה (projection) אשר נלמדות בתהליך האימון, מעבדות את ה-Inputs בהסתכלויות שונות. ישנן שלושה סוגים של מטריצות הטלה: “Query”, “Key”, ו-"Value". במאמר, גודל המטריצות הללו הוא 64 מימדים. אני מציע לזכור את הצבעים על מנת שיהיה קל להבין את התרשימים.
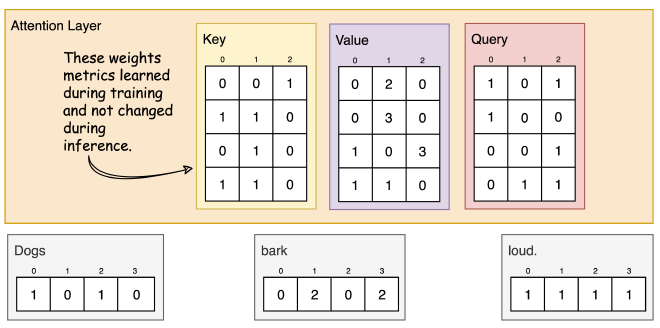
צעד 3: הכפלת המטריצות ב-Inputs #
עבור כל Input, נכפיל את ערכיו בכלל מטריצות ההטלה. את התוצאות של המטריצות Key ו-Value נכניס לשכבת ה-Attention, ואת מטריצות ה-Query נשמור בצד.
דוגמא לחישוב מטריצת Key של המילה Dogs:
[0, 0, 1]
[1, 0, 1, 0] x [1, 1, 0] = [0, 1, 1]
[0, 1, 0]
[1, 1, 0]
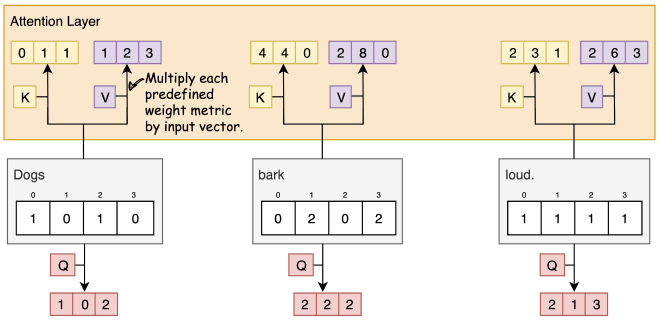
צעד 4: חישוב ציון Attention #
בשביל שנוכל לחשב ציון Attention של המילה הראשונה (Dogs) בהשוואה לשאר המשפט, נכפיל את ה-Query שלה Q1 (צבע אדום) בוקטורי ה-Keys (צבע צהוב) של כלל מילות המשפט. בעזרת הציון (Score) נוכל למדוד את היחס של מילים אחרות למילה הנעבדת - Dogs.
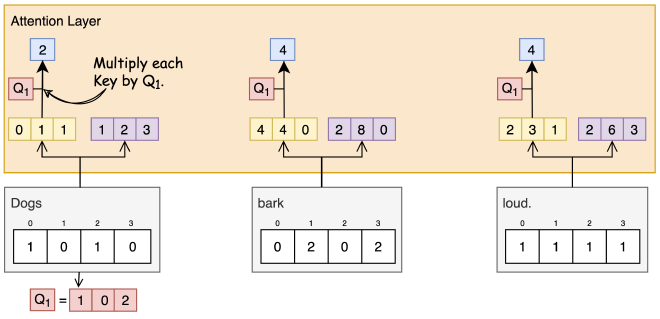
צעד 5: Scaling & Softmax #
אחרי חישוב הציון, נחלק את התוצאה בשורש הממד של ה-Key (למשל, מחלקים ב-8 אם ישנם 64 ממדים כמו במאמר) על מנת ״לעדן״ את הקורלציה בין Query ל-Key. למה? כדי שנוכל לשלוט בכמות השינוי שהמודל צריך לבצע במשקליו כחלק מהאימון (גודל הגרדיאנטים), ולמנוע Vanishing gradients (לדלג מעל מינימום השגיאה ולא להתקרב לפתרון אופטימלי). לשם הפשטות לא ציינתי את זה בגרף.
הציונים מועברים דרך פונקציית Softmax כדי להפוך אותם לערכים עם תדירות קבועה, כך שערכם יהיה בין 0 ל-1.
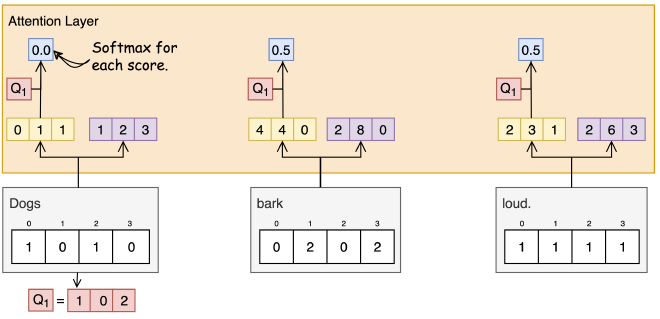
שלב 6: הכפלת Scores ב-Values #
הציון לאחר ביצוע Softmax (כחול) מוכפל בוקטור Value (סגול) המתאים לו.
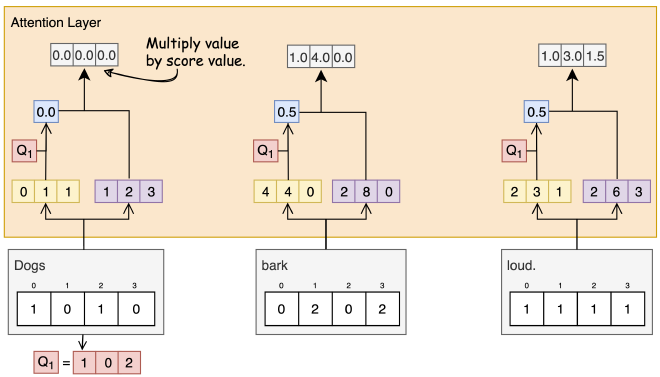
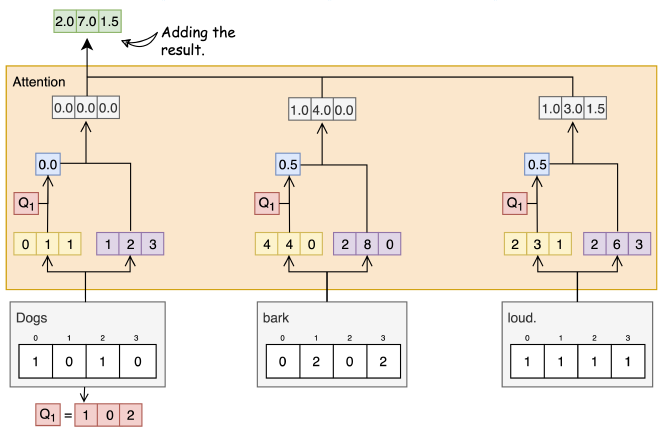
שלב 7: סכימת המשקלים #
ניקח את כל הוקטורים עם המשקלים של כל מילה ותוצאת ההכפלה, ונקבל את התוצאה של שכבת ה-Attention: כמה כל מילה משפיעה על מילה אחרת במשפט. בדוגמא שלנו התייחסנו רק למילה הראשונה Dogs.
[0.0, 0.0, 0.0]
+ [1.0, 4.0, 0.0]
+ [1.0, 3.0, 1.5]
-----------------
= [2.0, 7.0, 1.5]
הוקטור שקיבלנו מתאר את היחס בין המילה הראשונה עם כל שאר המילים במשפט: המילה ״Dogs״ משפיעה על עצמה 2.0, על המילה ״bark״ היא משפיעה 7.0, ועל האחרונה ״loud״ היא משפיעה 1.5 (מספרים מומצאים).
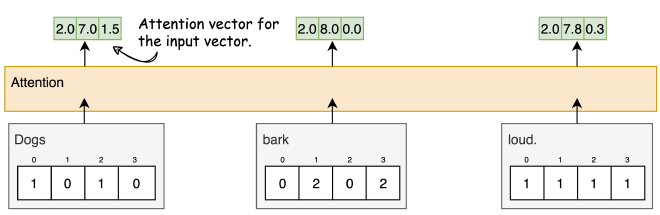
שלב 8: חישוב Attention לשאר המילים #
נחזור על השלבים שעשינו על מנת לחשב את ה-Attention של שאר המילים במשפט.
הכפלת מטריצות #
אחת מהיתרונות העיקריים בשיטת ה-Self-Attention שמאפשרת עיבוד וקטורי במקביל. במקום לבצע את הפעולות האלו (חישוב ציוני חשיבות, Softmax, הכפלה ב-Value וכו׳) עבור כל מילה וההשוואה שלה עם כל מילה אחרת מילה אחרי השניה, נוכל לבצע פעולות אלו במקביל עבור כל המילים במשפט באמצעות פעולות מטריצה-מטריצה.
למעשה, כשאנו מבצעים Self-Attention, אנו מכשירים שלוש מטריצות (Q, K, V) מהמשקלים שנלמדו ומהוקטורים של המשפט. אחר כך, באמצעות מכפלת מטריצות אנו מחשבים באופן מקביל את כל הקשרים (Context) בין כל זוגות המילים במשפט.
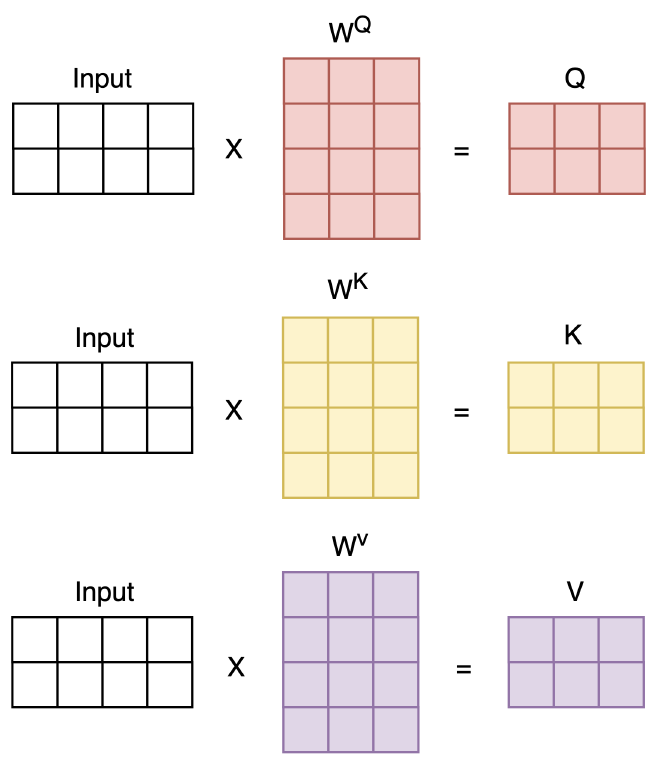
החישוב יהיה זהה, אלא שהפעם במקום וקטורים יהיו לנו מטריצות.
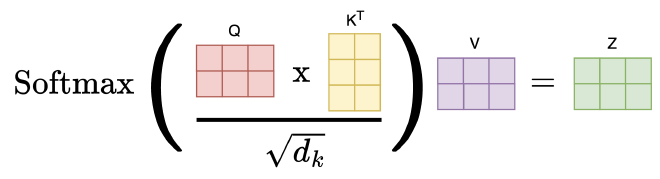
Multi-Head Attention #
במקום להגביל את הסתכלות המודל בשכבת Attention אחת, החוקרים גילו שניתן לקבוע מטריצות הטלה queries, keys, ו-values שונות כאשר לכל שלושה יהיה ראש Attention ייעודי ונלמדות בנפרד. בכך, במקום ששכבת Attention אחת תתמקד בהקשר אחד בתגובה לכל משפט, נוכל לבחון במקביל מגוון רחב יותר של הקשרים, והמודל יוכל ללמוד קשרים מורכבים יותר בין מילים במשפט ממספר זוויות שונות. במאמר, החוקרים הגדירו 8 “ראשים” לשכבת ה-Attention.
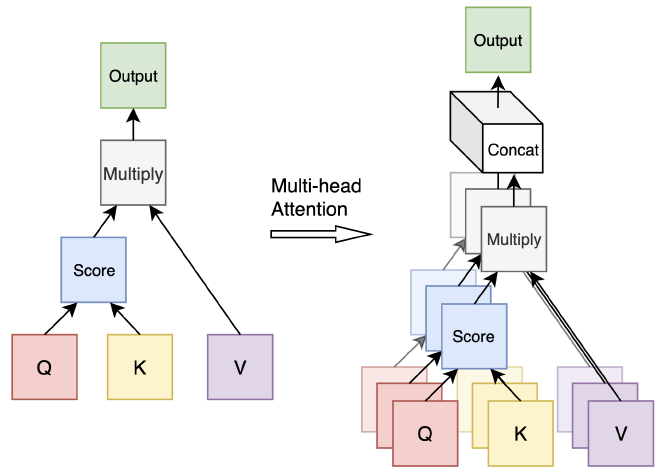
במהלך פעולת מנגנון ה-Multi-Head Attention, כל “ראש” מבצע חישובים עצמאיים של Queries, Keys ו-Values. זה מאפשר לכל ראש להתמקד במידע חלקי וייחודי מהנתונים הכלליים. בתהליך זה:
- כל ראש עובר תהליך בו הוא מפעיל פונקציית Attention על ה-Queries, Keys, ו-Values עם משקלים שונים שאומנו מראש, ובכך מייצר פלט שהוא וקטור Output ייחודי לאותו ראש.
- לאחר שכל הראשים מסיימים את החישובים שלהם, המודל מאחד את פלטי ה-Outputs מכל הראשים לווקטור אחד מורחב, על ידי הדבקה של וקטורי ה-Outputs אחד לצד השני, כך שהמידע מכל הראשים משולב למבנה אחד.
- השלב האחרון כולל הכפלת הווקטור המאוחד במטריצת הטלה נוספת, אשר גם לה משקלים ייחודיים. המטרה של שלב זה היא להמיר את הווקטור המאוחד למימדים המתאימים לשכבות הבאות במודל ולשלב את מה שנלמד בכל הראשי Attention יחד, מה שמאפשר להמשיך את זרימת הנתונים בתהליך הלמידה.
השימוש בתהליך זה של איחוד פלטים ממגוון ראשים מגביר את יכולת המודל לקלוט ולעבד מגוון רחב של נקודות מבט ופרטים, ובכך לשפר את הביצועים שלו בהבנת הטקסט.
Add & Norm #
אחרי שכבת Attention באה שכבת Add and Norm. בשכבה הזו, אנחנו נחבר את Input Embedding לוקטור שקיבלנו בסוף שכבת ה-Attention. טכניקה זו ידועה בשם ״Residual Connection״, ומטרתה היא לאחד את הידע ההקשרי שנלמד בשכבת ה-Attention יחד עם הקלט המקורי. בעזרת טכניקה זו, נעביר את הקלט המקורי לאורך שכבות עמוקות יותר של המודל, ושוב להימנע מ-Vanishing gradients.
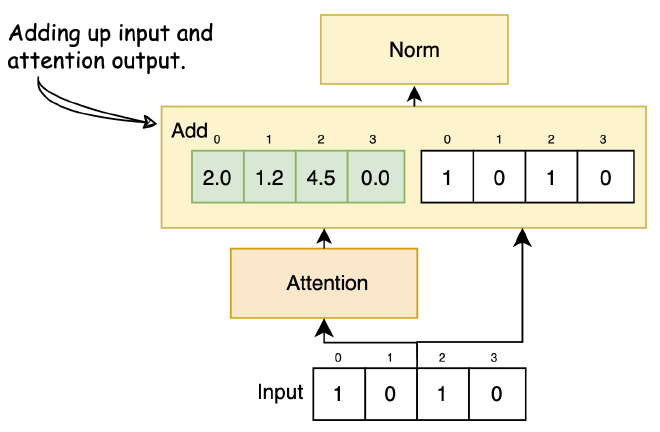
אחרי חיבור הוקטורים, הוקטור הסוכם עובר בשכבת Norm (קיצור של Normalization). יש הרבה דרכים לעשות נרמול, מתוכם שניים מרכזיים. Batch Norm מחשב את הממוצע ושונות לכל Feature ב-Batch. לדוגמה, ב-Batch של מילים, Batch Norm יחשב את הממוצע והשונות לכל Feature וינרמל כל אחת לפי הסטטיסטיקה הזו. השיטה מועילה ליציבות הלמידה אך פחות יעילה למודלים רצפיים כמו Transformers, שבהם כמות המילים למשפט משתנה.
Layer Normalization, לעומת זאת, מחשבת את הממוצע והשונות לכל ה-Features לכל משפט. לכל משפט מתבצע נרמול לפי הסטטיסטיקה של כל התכונות שלו. שיטה זו מתאימה במיוחד למודלים רצפיים ונמצאת כמועילה במשימות NLP. ארכיטקטורת ה-Transformer משתמשת ב-Layer Normalization כיוון שהיא לא תלויה בגודל ה-Batch ומטפלת בנתונים רצפיים ביעילות.
למה השכבה הזו נמצאה כמועילה ובשימוש בעוד מגוון מודלי שפה ולמידה עמוקה?
- Faster Training - משנה את ה-Scale של הערכים ודרך כך מפחיתה זמן אימון המודל.
- Bias - מונעת מהמודל לנטות לערכי קיצון.
- Weights Explosion - שומרת על טווח ערכים קבוע של משקלי המודל.
Feed Forward #
שכבת Attention זיקקה לנו את הקשרים בין המילים במשפט. השכבה הבאה, Feed Forward, מעבדת את ההקשרים הללו לכל מילה בנפרד, מוסיפה יכולת הסתכלות עמוקה יותר על הקשרים בין המילים וייצור לא-ליניארי של המשפט. שם השני של השכבה הינו fully connected feed-forward network (FFN). שכבה זו מעבדת כל מילה במשפט בנפרד, ובעזרת GPU היא מעבדת אותן במקביל.
ה-FFN מורכב משני שכבות Dense, כאשר פונקציית ההפעלה בינן יהיה ReLU. בעזרת ReLU נאפשר למודל לעבד את הנתונים בצורה שהיא לא-ליניארית, וללמוד דפוסים מסובכים - וזאת בדיוק מטרת שכבה זו. המימדים של פלט השכבה הזו זהה למימד של המילים שנכניס לה (d_model=512).
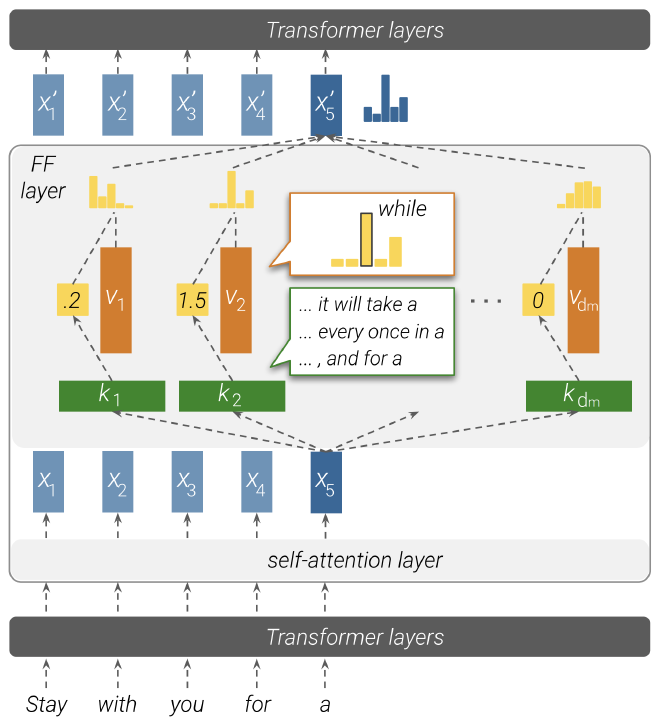
במאמר “Transformer Feed-Forward Layers Are Key-Value Memories” מציינים ששכבות FFN מהוות שחקן מרכזי באיתור דפוסים מרכזיים בטקסט. כמו שאפשר לראות בגרף, השכבות הנמוכות מאתרות דפוסים שטחיים (Shallow) כמו דברים תחבריים, וככול שעולים ברמות מגיעים לדפוסים סמנטיים (Semantic) עמוקים במשפטים.
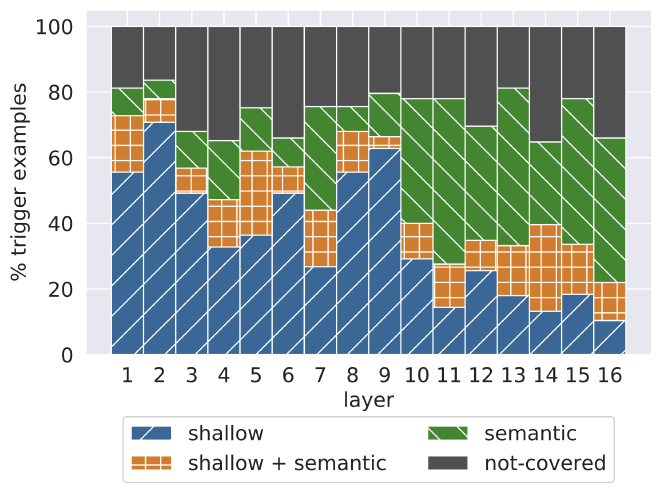
דוגמאות למשפטים לפי שכבות (הספרה מעל K מייצגת את עומק השכבה):

Add & Norm #
לאחר שכבת Feed Forward, יש לנו עוד שכבת Add & Norm כמו שהיה לנו לאחר שכבת ה-Multi-Head Attention.
סיכום Transformer #
דיברנו על המבנה הייחודי של בלוק ה-Encoder כחלק ממודל Transformer, עברנו על כל שכבה ושכבה ולמדנו איך הוא עובד. למרות שגם דיברנו קצת על בלוק ה-Decoder, חשוב לזכור שלצורך הדיון הזה, במיוחד כשמדובר ב-BERT, חלקו לא באמת רלוונטי. התמקדנו בחלקים שחשובים באמת להבין את אבני הבניין שמרכיבים מודלי Transformer, ובייחוד בשכבות ה-Attention שמחלצות ומנתחות את הקשרים והתלות בין מילים במשפט.
BERT #
BERT הוא מודל ששינה את המשחק בעולם של עיבוד שפה טבעית, וקדם למודלי שפה גדולים (LLM). בליבו, הוא מבוסס על רכיב של Encoder. זאת אומרת שהמודל הזה מתמקד בלמידה והבנה של טקסטים, בלי התעסקות בפרטים טכניים מעבר. השימושים של BERT בשוק רחבים ומגוונים, החל מהבנת טקסט, דרך תרגום אוטומטי, ועד ליצירת תשובות לשאלות באופן אוטומטי.
מבנה מודל BERT #
המטרה שלנו היא לזהות בין סוגי Class שונים, על בסיס משפטים. נפרק ונרכיב מודל BERT מופשט.
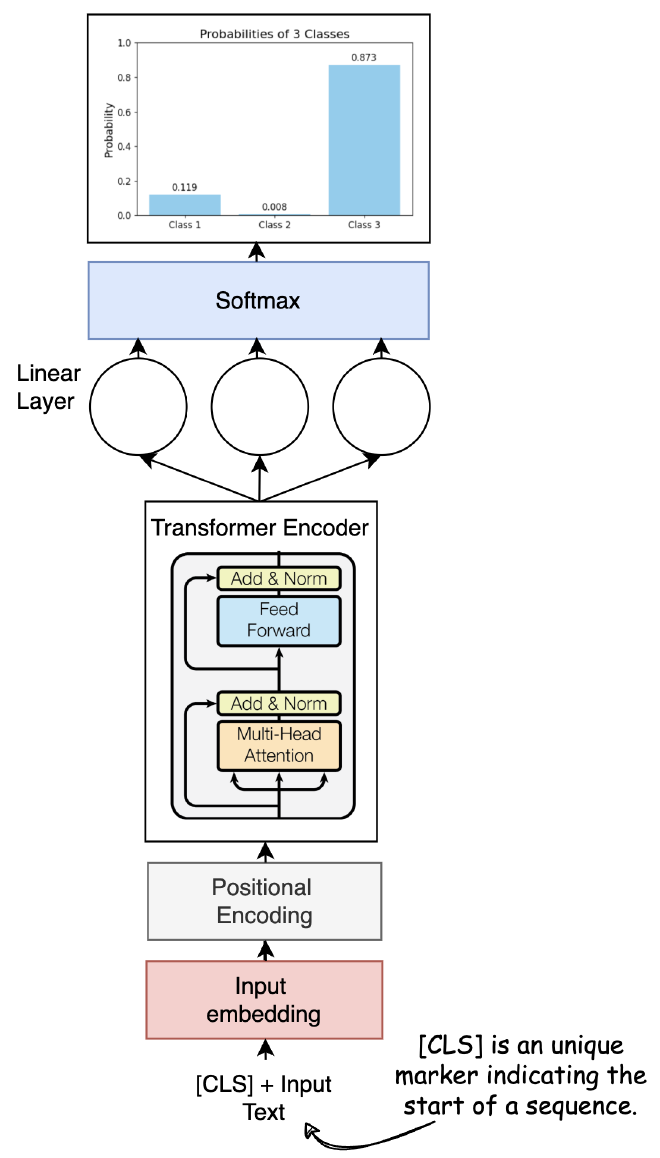
- Input Text - הטקסט הראשוני שנדרש לסווג.
- Tokenizer - עיבוד את הטקסט הקלט, חילוק ל-Tokens ש-BERT מסוגל להבין.
- הוספת [CLS] Token - הוספת [CLS] בתחילת הקלט. Token זה משמש לאגד את הייצוג של הקלט לסיווג שנבצע בהמשך.
- שכבת Embedding - מיפוי כל token לוקטור אחד.
- Transformer Encoder - ליבתו של BERT, עליו דיברנו בחלק הראשון של המאמר. ה-Embedded vector עובר דרך מספר שכבות של self-attention ורשתות feed-forward כדי לייצר embeddings עם קשרים ותלויות בין המילים במשפט. לצורך הפשטות, נחשב זאת כיחידה אחת.
- Output [CLS] Token - חילוץ את ה-embedding הסופי של האסימון [CLS] מתוך פלט ה-Transformer encoder.
- Linear Layer - שכבת fully connected שמקדמת את ה-embedding של האסימון [CLS] לוקטור שאורכו שווה למספר ה-Classes במשימת הסיווג.
- Softmax - פונקציית ה-softmax מייצרת התפלגות נורמלית על ה-Classes.
- Predicted Class - הניחוש הסופי, שהוא ה-class עם הסבירות הגבוהה ביותר שמתאימה למשפט. קיים ציון לכל class.
DistilBERT #
כדי להקל על העבודה שלנו ולהאיץ אותה, אנחנו משתמשים בגרסה מצומצמת של המודל, DistilBERT, שמציעה ביצועים טובים בזמן שהיא דורשת פחות משאבים ומהירה יותר בהרבה.
במאמר DistilBERT, a distilled version of BERT כתוב:
"DistilBERT retains 97% of BERT performance. Comparison on the dev sets of the GLUE benchmark. ELMo results as reported by the authors. BERT and DistilBERT results are the medians of 5 runs with different seeds."
תזכורת קטנה #
אחרי שיצרנו Synthetic Dataset בעזרת LLMs, נבצע Fine-tune על בסיסו, למודל DistilBERT. אני מזכיר, יש לנו sentiments_dataset שהוא אובייקט מסוג DatasetDict של ספריית datasets:
# Create DatasetDict
sentiments_dataset = DatasetDict({
'train': train_dataset,
'test': test_dataset
})
sentiments_dataset
DatasetDict({
train: Dataset({
features: ['text', 'labels'],
num_rows: 900
}),
test: Dataset({
features: ['text', 'labels'],
num_rows: 99
})
})
נעיף מבט אקראית במספר רשומות ב-Train:
# For the training set
train_sample = sentiments_dataset['train'].select(range(5))
print("Training Set First 5 Rows:")
for i in range(5):
print(train_sample[i])
{'text': '"Despite the recent events, making new friends [...]"', 'label': 0}
{'text': "Despite the weariness from past hurdles and the [...]", 'label': 0}
{'text': '"Discovering a new interest in shopping immediat[...]"', 'label': 1}
{'text': 'Despite the long-term grind and competitive pres[...]', 'label': 0}
{'text': '"The autumn leaves falling gently onto my face [...]"', 'label': 1}
על מנת שלסביבה תהיה גישה למשאבי Sagemaker ול-S3, נוודא שיש לנו את ההרשאות בסביבה ל-AWS. חשוב לשמור את המפתחות בקובץ env. אחרת לא נוכל לגשת למשאבים הללו.
import os
import boto3
from dotenv import load_dotenv
import sagemaker
# Load environment variables from .env file
load_dotenv()
# Use the loaded environment variables to configure AWS access
aws_access_key_id = os.getenv('AWS_ACCESS_KEY_ID')
aws_secret_access_key = os.getenv('AWS_SECRET_ACCESS_KEY')
aws_default_region = os.getenv('AWS_DEFAULT_REGION')
# Initialize a boto3 session
boto3_session = boto3.Session(
aws_access_key_id=aws_access_key_id,
aws_secret_access_key=aws_secret_access_key,
region_name=aws_default_region
)
Preprocessing #
כאשר חקרנו את המבנה של Transformers, הבנו ששכבת ה-Input Embedding מתרגמת טקסט לייצוג וקטורי. זהו בדיוק התהליך שאנו מבצעים כאן. אנו משתמשים ב-Tokenizer בשם distilbert-base-uncased, אשר מתאים בין המילים במשפטים של ה-Dataset לייצוג הווקטורי שלהם. אם מילה מסוימת מופיעה מספר פעמים, ייתכן שנצטרך להתמודד עם עודף מידע. לכן, אנו שומרים רק על ה-ID של המילה כהפניה ל-vocabulary המוכן מראש.
המשפטים ב-Dataset שלנו אינם בעלי אורך זהה, ומול דרישת BERT לקלט של שכבת ה-Input Embedding באורכים זהים, אנו מוסיפים בפונקציית ה-tokenize הוראה להוספת מרווחים (padding) באמצעות הפרמטר padding='max_length' . נסתכל על הטקסט הארוך ביותר ב-Dataset ונוסיף לטקסטים הקצרים יותר את ה-Token המיוחד [PAD], המיועד להגדלת הווקטור ללא הוספת משמעות סמנטית.
from datasets import load_dataset
from transformers import AutoTokenizer
# tokenizer used in preprocessing
tokenizer_name = 'distilbert-base-uncased'
# download tokenizer
tokenizer = AutoTokenizer.from_pretrained(tokenizer_name)
# tokenizer helper function
def tokenize(batch):
return tokenizer(batch['text'], padding='max_length', truncation=True)
# Get train and test from sentiments_dataset
train_dataset = sentiments_dataset['train']
test_dataset = sentiments_dataset['test']
# tokenize dataset
train_dataset = train_dataset.map(tokenize, batched=True)
test_dataset = test_dataset.map(tokenize, batched=True)
השלב הבא הוא המרת פורמט ה-Dataset ל-’torch’ עם עמודות input_ids, attention_mask, ו-labels .אנחנו נעבוד כחלק מתהליך האימון עם ספריית PyTorch, ובלי קשר המרת הפורמט מאפשרת טעינה ועיבוד יעיל של ה-Dataset. נוודא שלא איבדנו רשומות בדרך בעזרת ספירה פשוטה.
# set format for pytorch
train_dataset.set_format('torch', columns=['input_ids', 'attention_mask', 'labels'])
test_dataset.set_format('torch', columns=['input_ids', 'attention_mask', 'labels'])
print(f"The length of the train dataset is {len(train_dataset)} records.")
print(f"The length of the test dataset is {len(test_dataset)} records.")
The length of the train dataset is 899 records.
The length of the test dataset is 100 records.
העלאת ה-Dataset ל-S3 #
אחרי שעיבדנו את ה-Dataset, נעלה אותו ל-S3.
# s3 key prefix for the data
s3_prefix = 'samples/datasets/sentiments_dataset'
# save train_dataset to s3
training_input_path = f's3://{sess.default_bucket()}/{s3_prefix}/train'
train_dataset.save_to_disk(training_input_path)
# save test_dataset to s3
test_input_path = f's3://{sess.default_bucket()}/{s3_prefix}/test'
test_dataset.save_to_disk(test_input_path)
אימון המודל ב-Sagemaker #
האמת שזה פעם ראשונה שאני משתמש בשירות Sagemaker של AWS. מדובר על סביבה מנוהלת מקצה לקצה, שמה שאנחנו צריכים לעשות זה רק לטעון את המודל והכל יבוצע אוטומטית. הדבר הראשון שנגדיר זה ה-hyperparameters של המודל. בפועל הפרמטר היחיד ששיחקתי איתו הוא epochs, שאומר כמה פעמים המודל יחזור על ה-Training Datast. למול כך שמדובר על Dataset מצומצם, הגדרתי שהוא יחזור עליו 8 פעמים.
from sagemaker.huggingface import HuggingFace
# hyperparameters, which are passed into the training job
hyperparameters = {
'epochs': 8, # Changed it from 1 into 5
'train_batch_size': 32,
'model_name':'distilbert-base-uncased'
}
לאחר מכן, נגדיר huggingface_estimator שמכיל בעצם את כל ההנחיות בפועל איך לאמן את המודל. קובץ ’train.py’ מדייק את ההגדרות עוד יותר, ולא ניכנס אליו כחלק מהמדריך הזה. השתמשנו במכונה מסוג ml.p3.2xlarge שמכילה 8 vCPU, ו-61 GB Memory. העלות שלה לשעה הוא 3.8$. לבסוף, נגדיר את גרסאות הספריות השונות.
huggingface_estimator = HuggingFace(
entry_point='train.py',
source_dir='./scripts',
instance_type='ml.p3.2xlarge',
instance_count=1,
role=role,
transformers_version='4.26',
pytorch_version='1.13',
py_version='py39',
hyperparameters = hyperparameters
)
פונקציית fit מתחילה את תהליך האימון, עם הפניה למיקומים של ה-Dataset ב-S3. שימו לב שנקבל הרבה logs, וחלקם יהיו שימושיים בהמשך להבנת ביצועי המודל.
# starting the train job with our uploaded datasets as input
huggingface_estimator.fit({'train': training_input_path, 'test': test_input_path})
2024-03-12 19:55:54,252 loaded train_dataset length is: 899
2024-03-12 19:55:54,252 loaded test_dataset length is: 100
[...]
2024-03-12 19:58:17,831 Waiting for the process to finish and give a return code.
2024-03-12 19:58:17,831 Done waiting for a return code. Received 0 from exiting process.
2024-03-12 19:58:17,832 Reporting training SUCCESS
למול כך שמדובר על מכנה יקרה, נוודא שהיא לא באוויר:
sagemaker_session = sagemaker.Session()
sagemaker_client = sagemaker_session.sagemaker_client
job_name = huggingface_estimator.latest_training_job.name
response = sagemaker_client.describe_training_job(TrainingJobName=job_name)
print(response['TrainingJobStatus'])
Completed
נוכל לוודא את זה גם בעזרת האתר של Sagemaker. אם כתוב לנו שהמכונה “Completed”, זה אומר שאנחנו לא מחוייבים עליה.
Training result #
על בסיס ה-Logs שקיבלנו בתהליך האימון, נוכל לזקק תובנות על אימון המודל ועל האיכות שלו:
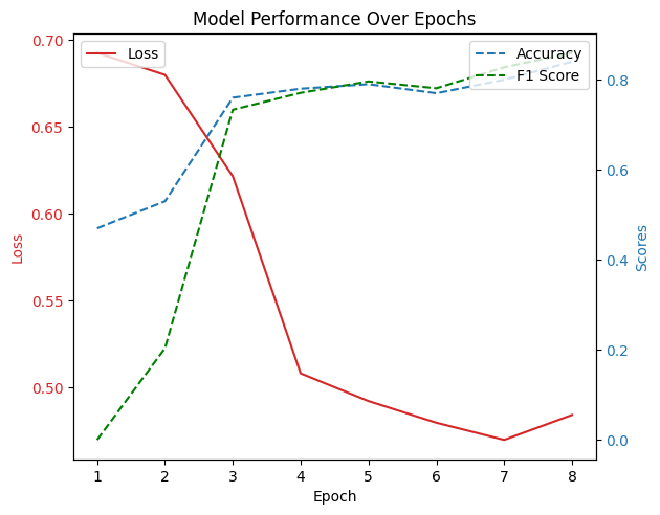
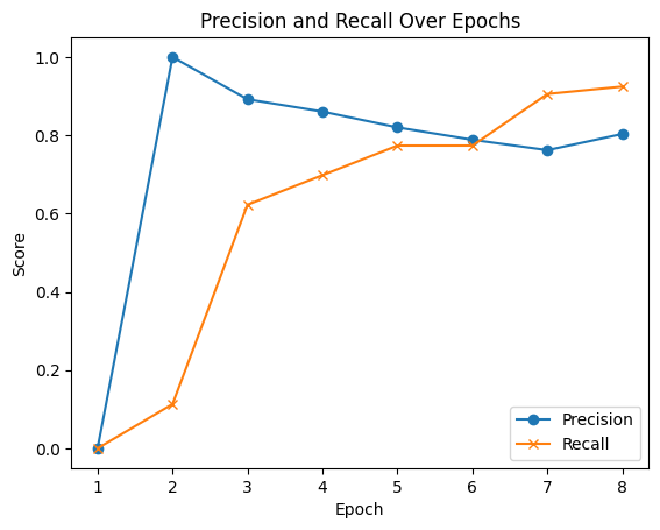
Loss - ב-epoch השלישי לערך, ה-loss יורד משמעותית, מה שמרמז על כך שהמודל לומד מהר בשלביו הראשונים. לקראת ה-ephoch השמני אפשר לראות קפיצה קטנה, מה שמרמז על התחלה של Overfit.
Accuracy ו-F1 Score - שני המדדים הללו עולים ככול שאנחנו מתקדמים בשלבי האימון, וזה סימן טוב לכך שהמודל נהיה יותר ויותר טוב למשימה אותה נדרש לבצע. ה-F1 Score, מדד מורכב יותר המאזן בין Precision ל-Recall, מציג מגמה דומה לדיוק (Accuracy), דבר המעיד על שיפור כללי ולא רק שיפור בסיווג של קטגוריה אחת על חשבון האחרת.
Precision ו-Recall - מדד Precision מתחיל גבוה מאוד אך לאחר מכן מתייצב, בעוד ש-Recall עולה באופן עקבי עד ה-epoch השביעי ואז יורד מעט. מה זה אומר בפועל? Precision (= דיוק) זה מדד שמראה לנו כמה מהתוצאות שהמודל שלנו סימן כחיוביות (למשל, ביקורות חיוביות) הן באמת חיוביות. Recall (= שיחזור) זה מדד שמראה לנו כמה מהדברים החיוביים שבאמת קיימים בנתונים שלנו, המודל שלנו גילה.
בגרף, המודל התחיל עם דיוק גבוה מאוד – מרמז שכל התוצאות שהוא קבע כחיוביות היו נכונות. אחרי זה, ה-Precision לא השתנה הרבה, אבל ה-Recall המשיך לעלות, כלומר המודל התחיל למצוא יותר ויותר מהדברים החיוביים שקיימים באמת בנתונים. זה טוב, כי זה אומר שהמודל לא רק שלא טעה, אלא גם התחיל לזהות טוב יותר את מה שהוא צריך לזהות.
ב-epoch האחרון, Recall קצת ירד – כלומר, המודל אולי החמיץ קצת או טעה יותר בזיהוי התוצאות החיוביות. גם כן נראה אידיקציה ל-Overfit, המודל למד בעל פה את ה-Dataset ולא יהיה טוב באותה המידה כשנשתמש בו על נתונים שלא ראה.
Deploying the endpoint #
אחרי שאימנו את המודל, נרצה להרים אותו ל-Endpoint על מנת שנוכל להשתמש בו מחוץ למחברת Python שלנו. בעזרת פונקציית deploy() נרים אותו למכונה.
predictor = huggingface_estimator.deploy(1, "ml.g4dn.xlarge")
הדגמה של שימוש במודל שנמצא באוויר:
sentiment_input= {"inputs":"worst day ever"}
predictor.predict(sentiment_input)
נמחק את ה-Endpoint. למה? כי היא באוויר כל הזמן ללא תלות בשימוש.
predictor.delete_model()
predictor.delete_endpoint()
Deploy Serverless Endpoint #
איך נוכל להרים Endpoint שיהיה באוויר בהתאם לשימוש? Serverless Endpoint זאת התשובה. ה-Endpoint יהיה באוויר כל הזמן, ויחכה להודעה ראשונית מהלקוח. לאחר ביצוע Cold Start שכולל הרמה בפועל של המודל ל-Endpoint (ודיליי של מספר שניות) ה-Endpoint תהיה זמינה כאילו היא נמצאת בשרת באוויר 24/7.
בשביל להרים מודל HuggingFace ל-Serverless Endpoint ב-Sagemaker, נעשה את השלבים הבאים:
- huggingface_model - הגדרה של המודל. ניגש ל-S3 על מנת לקחת את המודל וה-tokenizer שלו.
- serverless_config - הגדרה של ה-Endpoint. הבאתי לו זיכרון 6GB ואפשרות לעבוד במקביל 16 פעמים.
- deploy - הרמה של ה-Serverless Endpoint לאוויר.
import sagemaker
from sagemaker.huggingface import HuggingFaceModel
from sagemaker.serverless import ServerlessInferenceConfig
from sagemaker.huggingface.model import HuggingFaceModel
# Specify the S3 URI of the model.tar.gz file
model_data = 's3://sagemaker-us-east-1-XXXXXXXXXXXXX/huggingface-pytorch-training-2024-03-12-19-49-02-465/output/model.tar.gz'
role = 'arn:aws:iam::XXXXXXXXXXXXX:role/service-role/AmazonSageMaker-ExecutionRole-20240225T000555'
# Create the HuggingFaceModel object
huggingface_model = HuggingFaceModel(
model_data=model_data,
role=role,
transformers_version='4.6.1', # Specify the appropriate version
pytorch_version='1.7.1', # Specify the appropriate version
py_version='py36', # Specify the appropriate Python version
)
# Specify the serverless inference configuration
serverless_config = ServerlessInferenceConfig(
memory_size_in_mb=6144, # Adjust based on your model size
max_concurrency=16, # Set the maximum concurrency for your endpoint
)
# Deploy the model as a serverless endpoint
predictor = huggingface_model.deploy(serverless_inference_config=serverless_config)
# Now you can use the `predictor` object to make predictions
---!
בצילום מסך תוכלו לראות שני Serverless Endpoint באוויר בממשק של Sagemaker:
נבדוק את ה-Serverless Endpoint על דוגמא:
input = """"
'I rented I AM CURIOUS-YELLOW from my video store because of all the controversy that surrounded it when it was first released in 1967. I also heard that at first it was seized by U.S. customs if it ever tried to enter this country, therefore being a fan of films considered "controversial" I really had to see this for myself.<br /><br />The plot is centered around a young Swedish drama student named Lena who wants to learn everything she can about life. In particular she wants to focus her attentions [...]'
""""
sentiment_input = {"inputs": input}
predictor.predict(sentiment_input)
[{'label': 'LABEL_0', 'score': 0.9690449237823486}]
Evaluate BERT on IMDB Dataset #
אתר IMDB בשיתוף Stanford חיברו Dataset של תגובות צופי סרטים. כל תגובה מתוייגת האם היא שלילית וחיובית. רציתי לראות האם יש התאמה בין המודל שאומן על בסיס תוצאות מודלי שפה לבין Dataset שנוצר על ידי אנשים.
הורדת Dataset #
השלב הראשון הוא לטעון את ה-Dataset, בעזרת ספריית datasets איתה השתמשנו קודם לכן.
from datasets import load_dataset
# dataset used
dataset_name = 'imdb'
dataset = load_dataset(dataset_name)
dataset
DatasetDict({
train: Dataset({
features: ['text', 'label'],
num_rows: 25000
})
test: Dataset({
features: ['text', 'label'],
num_rows: 25000
})
unsupervised: Dataset({
features: ['text', 'label'],
num_rows: 50000
})
})
נוכל לראות שה-Dataset מכיל 100 אלף רשומות, מתוכם 50 אלף מתוייגים.
סיווג 25 אלף רשומות #
לאחר שהורדנו אותו, השלב הבא הוא לעבור עליו ולראות מה המודל חוזה. הקוד שעושה את המטרה הזו מחולק לשלושה חלקים:
- trunc_text - קיצור הטקסט לכמות המקסימלית של ה-Tokens שהמודל יכול לקבל. המקסימום הוא 512, אבל לקחתי 450 לשם הטוב.
- make_prediction - סיווג המודל לטקסט, האם הוא שלילי או חיובי. הפונקציה הזו מחזירה Dict שמכיל את התחזית, מה שהיה אמור לחזות ורמת ה-Confidence.
- ThreadPoolExecutor - תהליך Thread שמבוצע 16 פעמים במקביל, סורק את ה-Train data, ובודק מה המודל חושב שהם. גודל ה-Train הינו 25 אלף רשומות - גדול אמרנו?
from transformers import AutoTokenizer
from concurrent.futures import ThreadPoolExecutor, as_completed
from tqdm import tqdm
tokenizer_name = 'distilbert-base-uncased'
tokenizer = AutoTokenizer.from_pretrained(tokenizer_name)
def trunc_text(text, max_length = 450):
# Truncate the tokens to the maximum length (512 tokens)
# Reserved space for special tokens like [CLS], [SEP]
# Tokenize the text
tokens = tokenizer.tokenize(text)
truncated_tokens = tokens[:max_length]
# Convert the truncated tokens back to a string
truncated_text = tokenizer.convert_tokens_to_string(truncated_tokens)
return(truncated_text)
# Function to make prediction and format result
def make_prediction(item):
text = item['text']
true_label = item['label']
trunc_input = trunc_text(text)
text_input = {"inputs": trunc_input}
prediction_result = predictor.predict(text_input)[0]
predicted_label = 0 if prediction_result['label'] == 'LABEL_0' else 1
confidence = prediction_result['score']
return {
'text': text,
'label': true_label,
'prediction': predicted_label,
'confidence': confidence
}
# Initialize list to hold processed data
data = []
# Using ThreadPoolExecutor to run multiple predictions in parallel
with ThreadPoolExecutor(max_workers=16) as executor:
# Setup future tasks
future_to_item = {executor.submit(make_prediction, item): item for item in dataset['train']}
# Process as they complete
for future in tqdm(as_completed(future_to_item), total=len(dataset['train']), desc='Predicting'):
result = future.result()
data.append(result)
Predicting: 100%|████████████████|
25000/25000 [21:03<00:00, 19.78it/s]
אחרי המתנה של 21 דקות, סיימנו בהצלחה את עבודת סיווג הרשומות.
תוצאת ה-Evaluation #
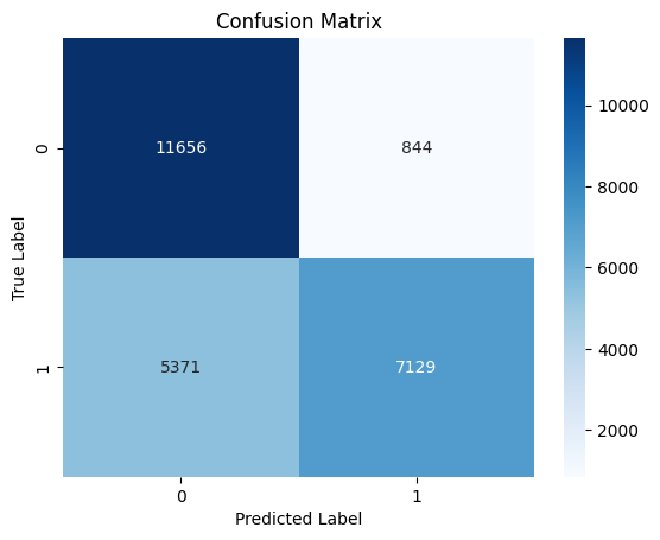
Confusion Matrix - אפשר לראות במבט זריז שלמודל אכן יש כמות גבוהה של תחזית נכונה, true positives ו-true negatives. עם זאת, למודל יש לא מעט false positive, דבר שיכול להראות על כך שהמודל סוטה לכיוון השלילי ולא הצליח לרדת לשורש ההבנה שציפינו לה.
ROC - בגרף מסוג זה, אם ה-AUC קטן מ-0.5, זה אומר שעדיף להטיל קוביה מאשר להשתמש במודל, או להשתמש בתוצאה ההפוכה שלו. נוכל לראות בבירור שיש פה בעיה.
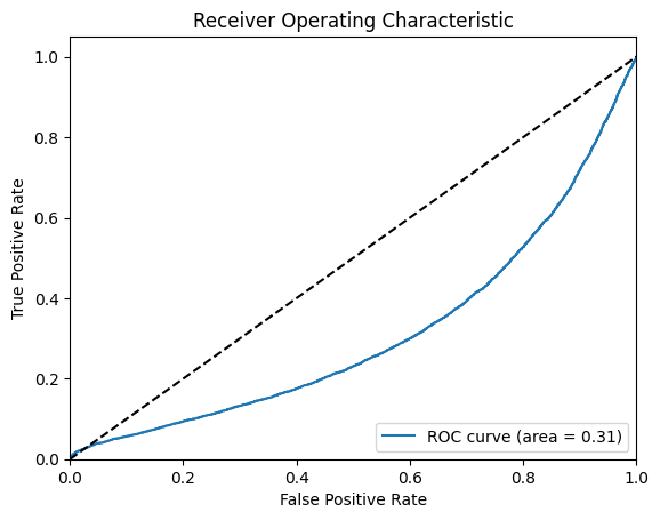
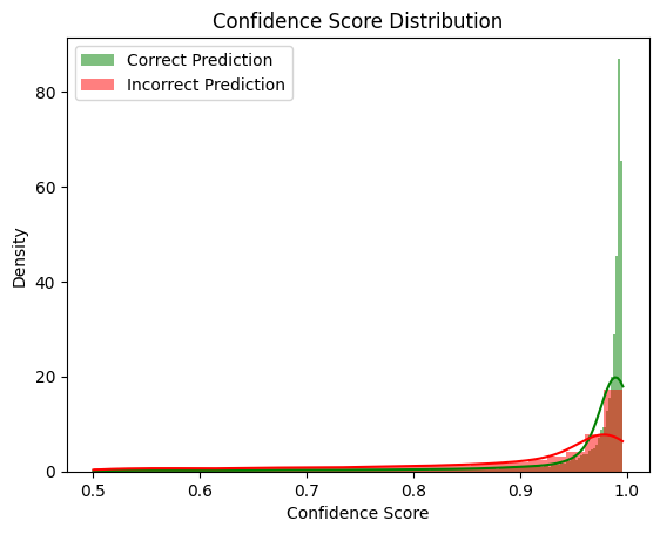
Confidence - חלק מבעיות המודל הוא רמת הביטחון שלו בסיווג הטקסטים. נוכל לראות שיש קשר בין רמת הבטחון שלו לבין כמה שהוא צודק בפועל. בנוסף, אפשר לראות שיש לא מעט רשומות בין 0.5 ל-0.9.
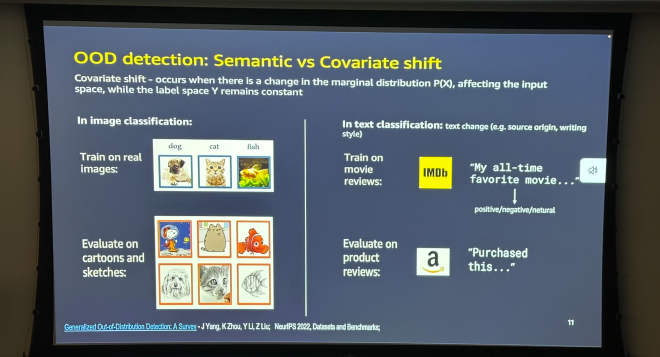
Covariate Shift #
רצה הגורל, ובזמן כתיבת שורות אלו הלכתי ל-Meetup ב-AWS (קישור להקלטה). המרצה הראשון דיבר על הבעייתיות של אימון מודל Classification על IMDB ולבדוק בפועל על Amazon. עולם קטן, כי זה בדיוק מה שאני עשיתי, רק על סטרואידים.
מסקנות #
אם הגעתם עד לפה, קודם כל רציתי להגיד תודה!
עכשיו ברצינות. מדובר על אתגר, שהוכחנו שהוא אפשרי אבל לא בצורת היישום הנוכחית. My top 5:
- Prompt - אחרי שיצרתי את ה-Dataset, ראיתי שכל המשפטים שנוצרו הם סיבה ותוצאה. מבנה מאוד מאוד קבוע, לא רנדומלי ולא מגוון. אומנם הנושאים, ונקודות המבט של המשפטים שנכתבו על ידי מודלי השפה שונים, העובדה שהמודלים עשו אחד לאחד מה שביקשתי, גרעה מאיכות המודל בפועל. להמשך, הייתי מסווג את IMDB לקטגוריות, ומוסיף Few-Shot ל-prompt. לאחר מכן הייתי חשוב על עוד אפשרויות של יצירת רשומות רנדומליות ולא על פי תבניות.
- Hyperparamaters Tunning - רואים בבירור שנדרשת עבודה נוספת על אופטימיזציית תהליך אימון המודל. ייתכן שיש לנו מעט מדי רשומות, והמודל בשלב מסויים התחיל ללמוד את ה-Dataset בעל פה.
- Evaluation Dataset - קיים קושי רב להשוות בין מודל שאומן על Dataset מבוסס LLM לבין Human made dataset.
- Confidence - נדרשת העמקה על בטחון המודל. איזה סוג של רשומות הוא לא יודע לסווג? למה?
- Humans - עם כמה שזה נשמע כיף, הגורם האנושי זה משהו שקשה להעתיק ולחקות. גם עם המודלי שפה המתקדמים בשוק. לדעתי הוכחת היכולת קיימת, עם זאת נדרשת לא מעט עבודה מעבר.